I successfully created/imported an OSM graph with the default CarFlagEncoder.
Also I successfully created the LocationIndexTree. I can use it to findClosest() and it work great.
Then I create a QueryGraph, lookup() all those List<QueryResult>.
Then I create a DijkstraOneToMany to build a time matrix.
This is all working great and real fast!!!
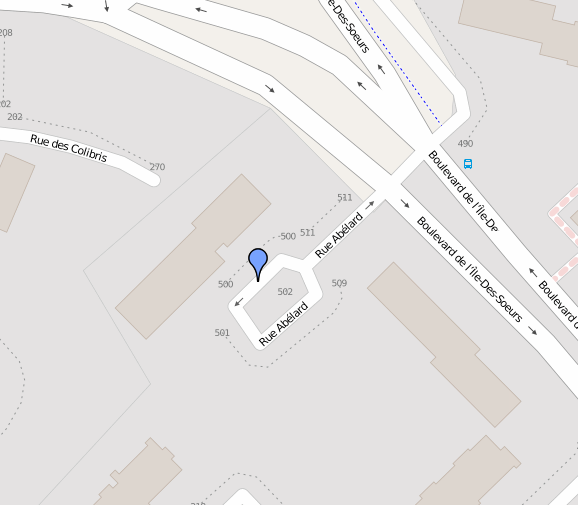
But, sometime, OSM data is wrong,
for example, here, the “Rue Abélard” street is NOT supposed to be one way:
Because of this, DijkstraOneToMany.calcPath() always return path.isFound() == false when routing to this node.
Is there something I can do to workaround this situation ?
Also, on your Directions API Live Examples, you seems to be able to workaround it, by stopping as close as possible but not going into the wrong way, this is a very acceptable way to workaround the problem, I would like to be able to do the same.
I guess I can create a CarFlagEncoder subclass, but I do not know where to start.
After importing the OSM, I did this, and the routing works like a charm!
Bonus: the files on disk are smaller after that too!
PrepareRoutingSubnetworks preparation = new PrepareRoutingSubnetworks(storage, encodingManager.fetchEdgeEncoders());
preparation.setMinOneWayNetworkSize(200);
preparation.doWork();
Two related questions:
Just to understand what happened here: the minOneWayNetworkSize is the minimum cardinality (of node) a subgraph must have in order not to be cut out from the graph ?
If the answer to (1) is yes: so it is possible that somehow I still get stuck in a subgraph with a cardinality >= 200 nodes. So I wonder if there is a way I could have worked around the problem without needing to re-import the graph? Maybe by finding alternative nearest nodes ?
yes, exactly. Keep in mind that there are two properties: the undirected and the direction (oneway) property where the oneway is 0 and the undirected is 200 by default currently.
Yes (like between Europe and USA ;))
Joking aside, of course this could still make problems, but they are rare then. There are the following different solutions:
one could implement to find not only one start and end edge and populate the algorithms with multiple start and end nodes and find potentially multiple best paths. But the biggest problem here is how to weight the snapping distance compared to your normal weight which is often not just distance but e.g. time or “priority” etc. Exactly the same problem we have in our map-matching component btw where we have already implemented a ‘find k’ nearyby locations
another solution would be to never set access to false to an edge and instead still allow access on forbidden edges. This requires a post-processing step where the forbidden edges are removed. The advantage is that this could be added to our current strategy relative easy. The minor problem could be that the snapping then could be wrongly guided into these traps leading to several unnecessary ‘forbidden’ edges in the path.
We just decided for the ‘simplest’ solution but investigating this problem further could be worth the effort!
I like the idea of having multiple start/end nodes.
I understand the problem of weightning the snapping distance.
But I guess only considering the distance would be ok, since the gap between the query point and the snap point is usually not on a road.
Anyway, for now (for me), I think your ‘simplest’ solution, is enough.
In a normal situation, we do not want ‘forbidden’ edges to be used.
This is just to workaround the fact that some edges are wrongly flagged as oneway in the OSM data.
In my testing, if the OSM data is correct, the Algo is always able to find a path.
Thank you for your time, it is really appreciated!
What do you mean with ‘not on a road’? And what do you do if you found two routes A and B with weight(A)<weight(B)
but they snapping to route A is far away: snappingDistance(A)>snappingDistance(B)?
(Actually the snappingDistance is the sum from start and end or something)
Exactly. And that is also the reason the option is disabled by default. But sometimes, if you deal with trucks, you can easily create such subnetworks unintended even if the data is correct.