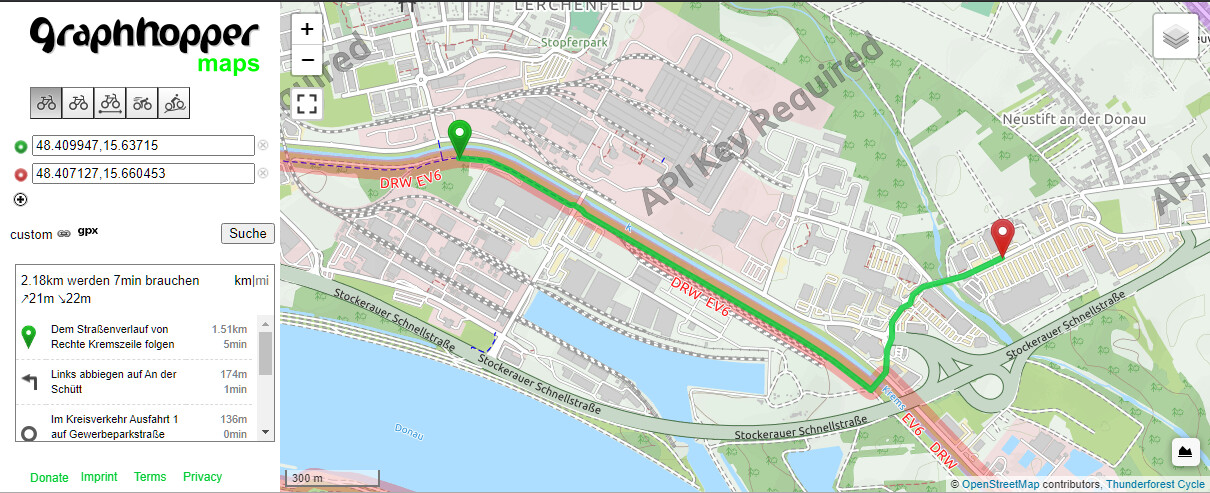
I have started to play around with the 3.0 custom routing and I have a basic question which I could not answer myself by reading the source code: The question is why a custom query with an empty ruleset does not lead to the same result compared to the flag encoder result.
To illustrate my question here is the ordinary request for bicycle:
So currently we assume all priority changes in the custom model, which is good in theory, but in order to make the migration better (and simpler) we need to provide a solution for this issue. Best solution if we could directly use the bike$priority encoded value like:
(which we could then use on the server-side custom model and so a query to bike would use it by default). But this requires some internal changes. Still it should not be that hard. Also this would be a nice feature for other encoded values.
Thanks for this use case. As my current plan was not to allow (mostly) arbitrary statements like in the if-clause, would it work for you if you could do something like:
weighting=fastest uses PriorityWeighting which is a bit confusing. But PriorityWeighting is what we want to compare our CustomWeighting with.
The "distance_influence": 0 is required for our custom model when we want to make it behave identical as we do not have a distance factor in PriorityWeighting
a maximum value is required in general for the getMinWeight estimate to make A* behave correct (and faster)
ugly: a maximum entry is required in set_to although we could easily determine the maximum of the EncodedValue. But we cannot know if the formula is e.g. x or 1/x. We could assume a default maximum of 1 to make it a bit easier but it would not help here.
a maximum of 1.5 is required as the best value can be 1 plus the 0.5 (see PriorityWeighting)
it is not possible to request a custom_model with a maximum above 1 from the client-side but we can still put this server-side in the custom bike profile (config.yml)
we have a bug in CustomWeighting that does not account for the minFactor as we do in PriorityWeighting and need to fix it before we can properly compare both results.
So it is a bit harder than expected to migrate from fastest to custom weighting but doable and will offer many advantages
Yes, this might be the cleaner solution although I’m unsure if a conditional set_to will be used often in practise and it would always end up as "if":"true". Another more fundamental change would be to make the conditional expression (if, else-if) optional for all operations (set_to, multiply_by, limit_to)
Not sure if this is an actual problem but as then the value can be a string or a number it might be a problem for the API docs or clients.
Furthermore for the client-side I see no way around the additional maximum entry as we use LM or require at least a follow up limit_to?
To me it seems like a rather obvious use-case to set explicit speeds depending on some condition, like certain road_classes or areas.
What would be the advantage of this?
I probably don’t understand the problem yet, but for the other operators we already have this check on the server-side: We evaluate one statement after the other and if the resulting speed exceeds the max speed we reject the custom model. Also e.g. for server-side custom models we do not have this LM max restriction so it would be better to not adjust the syntax because of this restriction.
Ok, yes, indeed. Useful also to really overwrite initial speed values (unlike limit_to).
What would be the advantage of this?
that you can avoid the "if": true workaround and be more clear about the intent.
I probably don’t understand the problem yet
The problem is not about the set_to operator but the fact that it contains a “dynamic” encoded value. And we need to ensure the correctness of A* and if the encoded value contains values bigger than 1 (maximum priority) for some edges and we use set_to: bike$my_encoded_value
then the priority in the graph can be lower than what we estimate with getMinWeight which could lead to suboptimal routes for all A* algos.
I would be ok to enforce a limit_to for all queries with an encoded value in its expression but it would have to be an unconditional limit_to with a static value:
It would be less ugly when the "if": true is omitted as we would also need this for multiply_by and limit_to with expressions.
Another solution would be to log the maximum value of the EncodedValue. Or we use the maximum possible value via getMaxInt or getMaxDouble, but then the performance could be affected if this maximum value is far above the used maximum e.g. if a max speed of 140km/h is required we could have a maximum of the underlying EncodedValue of 256km/h due to the bit range. Or we store an additional max value in every EncodedValue - could also be useful for things like: Max speed can get exceeded due to rounding error · Issue #2322 · graphhopper/graphhopper · GitHub. But the problem is then that we mix application and storage too much (we did this with the default value and this was something we had to get rid of fast).
It comes without any API change and will "just work"™ for custom profiles. The only downside is that the priority EncodedValue requires 4 instead of 3 bits and due to rounding errors there might be tiny differences between the old and new behaviour. I’m currently investigating the tests that required a change and if the routes still look reasonable. It would be very appreciated if you can have a look and test it out in real world for your cases too.
I looks as if the higher the factor becomes the more it avoids segments with higher priority. A factor of 0.75 still prefers the Eurovelo 6 and with 0.8 one gets the same result as compared to the first screenshot.
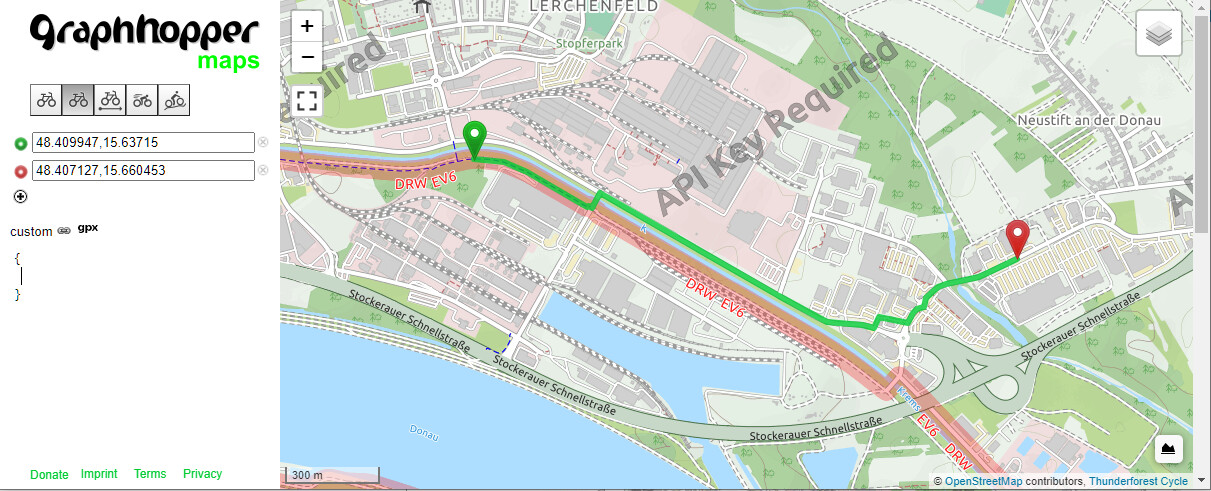
I just tried this route with my proposed PR (branch include_priority) and I cannot see a difference anymore. Can you confirm that this works for you (at least for this case) ?
for a really identical behaviour otherwise you get a similar behaviour to weighting: short_fastest. As the default distance_influence is 70 for custom weighting.
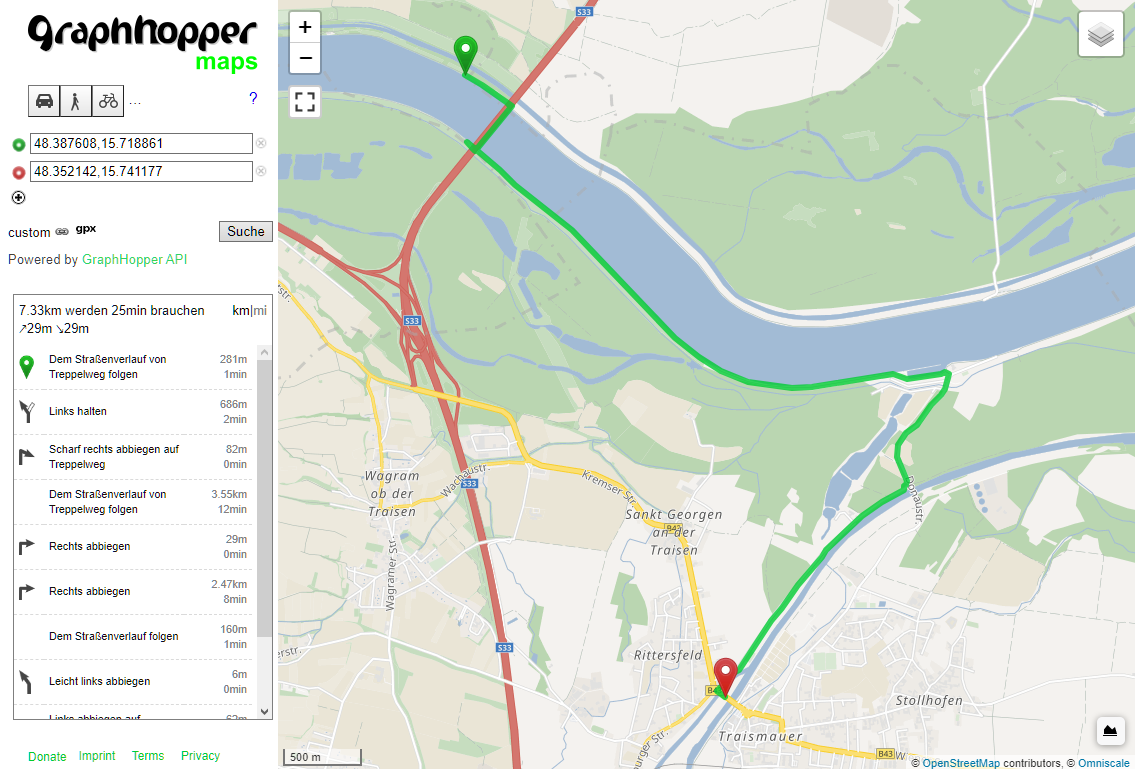
I still have one more question: What is the best rule to increase the influence of the existing priority? E.g. if I want to go an the “best” priority ways and take longer detours into regard. I would assume that it is now possible to prefer “rcn” cycle relations, but I couldn’t mange this with a custom rule.
This rule does something similar to what I intend:
Yes. The problem is the landmark algorithm where only a decrease of the edge weights is allowed to avoid incorrect/suboptimal routes. But when we know that the edge weights are bigger already while the LM preparation then a factor bigger 1 is fine.
when the factor is in the allowed range from some small value of 0.0001 to 1.0.
Did you try a factor bigger than 1 for server-side?

 and will offer many advantages
and will offer many advantages