Hi Stefan and others!
I created this separated topic to separate my original problem with the upraised need of making jsprit more flexible regarding Jobs and Activities.
My original post on this topic was:
I saw, that the code often uses instanceof at several places to make Job type dependent tasks. Using instanceof intensively (in code where decision is made) is a sure sign that the encapsulation is somehow violated. It leads to extension-anomaly: introducing a new class in the inheritance tree would be a nightmare, because lots of class implementations would have to modify. (Additionally, when these instanceof-driven if-branches are not terminated by an “else throw exception” branch, even finding out all the places to contribute into would be hard.) Why is this dangerous? Because what these codes do is really a type implementation-specific function, so their right place would be in the type implementation (or in a class factored from the implementation).
I offered my help for the refactor to Stefan (on private), and started to do some behavoiur-equivalent refactoring already. But as Stefan suggested, if we take the time and step over the limitations, we should think it over first.
Here are some of my thoughts (as a initiation of a discussion):
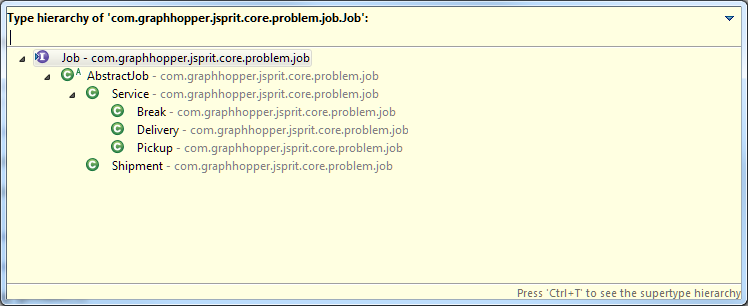
There are two types we are talking about: Jobs and Activities.
As far as I see, there are 4 types of activities:
- Pickup: where there is a cargo load, so capacity is reserved
- Delivery: where there is a cargo unload, so capacity is freed up
- Service: where there is no cargo manipulation (althogh there could be cargo requirement), so there is no change of capacity
- Exchange (beter name required): where there is both a cargo unload and load, so the capacity could either be reserved or freed.
As far as I see, all job could be broken down to this four activities, and these are differ mainly on the type of cargo manipulition.
Jobs, on the other hand, is something which describes a business use case. Service and Shipment is two examples, but Shipment with backhaul is a third one, and I’m sure there are still others. This is the interface the user may extend.
I tried to collect the (abstract) properties of the jobs:
- They all break down to a well defined set of activities (with order defined)
- They should be handled by the same vehicle on the same route
The main aspect of this interpretation of the meaning of Job and Activity, that only the Jobs should be offered for extension.
This means that to achive flexibility and extensibility all we need to do is allow the user the following logical steps are needed:
- Define the four activities
- Give the responsibility of breaking down jobs to activities to the Job implementations (I’ve already prototyped it in my fork of the code and it cleaned up a lot of code.)
- Clean up the tight coupling of Job by eliminating instanceof references
- Make the internal constraints/insterter/ruiner implementations to keep together and in the right order of the activities of any Job. (This is abstract, so any new job will fit in well. Even beter, that this requirement is simple – I don’t know if the implementation is the same)
As it seems, the internal constraint/cost implementations should mainly concentrate on intra-job relationships. All inter-job relationships best to left to the user to define in the future, too.
However, there are some questions this solution raise up, especially about the boundaries of the Jobs:
Is there a need to support not completely sequencial activities within a Job or can they be represented with several jobs and constraints between then?
An example: do we need to support a Job, where there are two pickup activities and a delivery/service. The pickups should preceed the delivery, but the order of two pickups are indifferent. Or is it three Jobs with constraints?
The first is much more flexible, but the internal implementation of the internal part would be much more complex (as far as I feel).
Do we need to support a stronger ordering among the activities of a Job, where the immediate neighbourhoodness is required?
I feel that the answer is no, because this could always be united into one ability, and would be hard to handle them (keeping them together).
So this is my first though on the subject.
I am looking forward on your ideas and your critics. ![]()
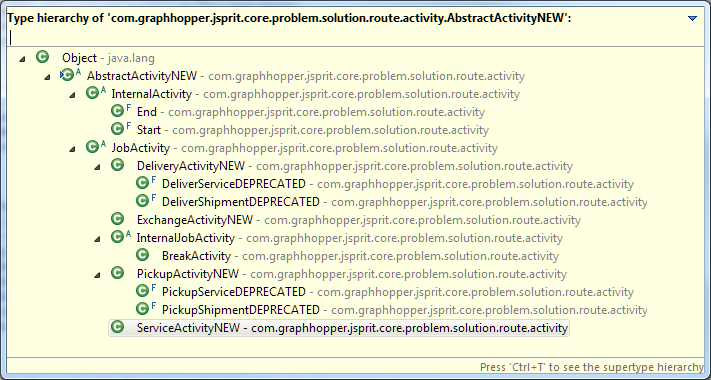
UPDATE1: Of course, although I forgot, there is a fifth Activity type: Internal, which is the common ancestor of the specialized activities used internal, such as Break.