I work for for wecity - a mobile app which rewards sustainable mobility - and I’m using the map-matching tool for performing various types of data analysis on the trips performed, recorded and uploaded by the users.
One of the most frequent analysis I perform concerns answering the question “which road segments (of the OSM graph of a city) are crossed more frequently?”
The approach I use is roughly this:
-
- I receive sets of “raw” GPS points (subject to error, thus in general not laying on any OSM edge), each of them representing a trip performed by a user.
-
- I use a python script (which sends a map-match request to my locally hosted graphhopper) to convert such trips into sequences of points that are actual nodes of the OSM graph
-
- The same python script converts the sets of map-matched points to sets of edges (by aggregating subsequent points : each edge is intended as an unordered set of two points), and store them into a postgis database.
-
- I use spatial queries for grouping the records by edge, and counting how many times every single edge appears (note that given the fact that edges are stored as unordered sets of points, the grouping is not sensitive to the orientation. E.g. edges [1,2] and [2,1] will result as the same edge for concerning grouping and counting).
The analysis runs successfully but I noticed that in some areas of the I had different overlapping edges laying on the same road segment, making the crossings count ambiguous and inaccurate for these minor parts of the graph.
I thought that this was due to response simplification: some of the points resulting from the map-match are indeed discarded as long as 1. their removal does not affect the resulting trip shape too much and 2. they are not junction nodes. This seemed plausible as the map matching processes of two trips which overlap in some parts may choose to remove different sets of points during the simplification due to the differences in the “overall” shape of the two trips.
I managed to disable the simplification. Nonetheless, the results were not quite as expected. After disabling the simplification my map-matched trips database contained approx. 6 000 000 lines (one line for each edge that was crossed in one of the map-matched trips) - that’s reasonable, it resulted in 4 500 000 lines before - but after the grouping it only reduced to 2 600 000 unique edges, while when the simplification was allowed the unique edges resulted to be only 100 000. Things are significantly worse this way.
To investigate the issue, I plotted the map-matched nodes from 10 trips that overlap in some parts in order to check if the map- matching process returned the same nodes when suggesting the same path. This is what I obtained (I suggest to use the link, the popups help understanding the map content which is hard to explain with a static image):
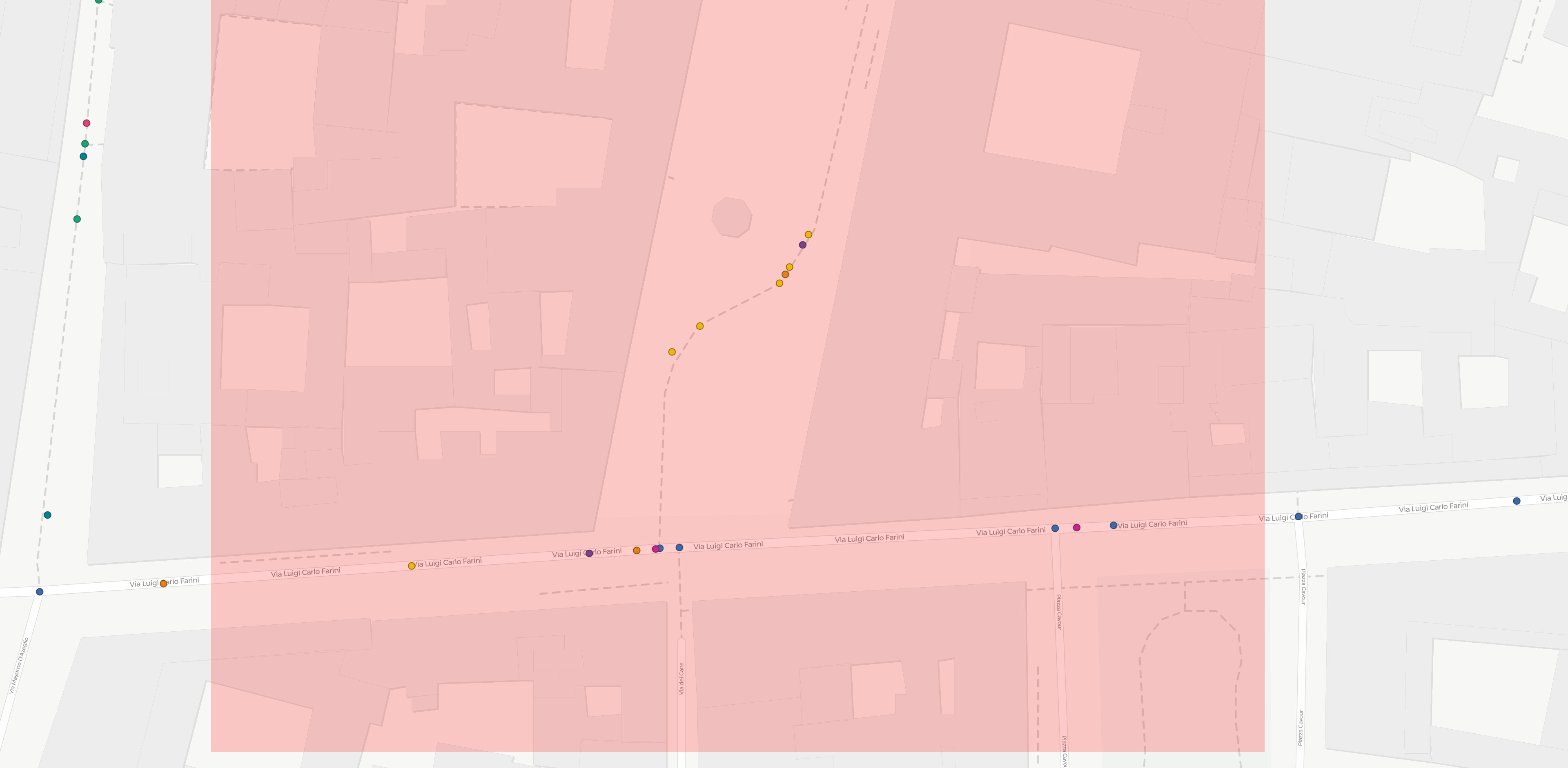
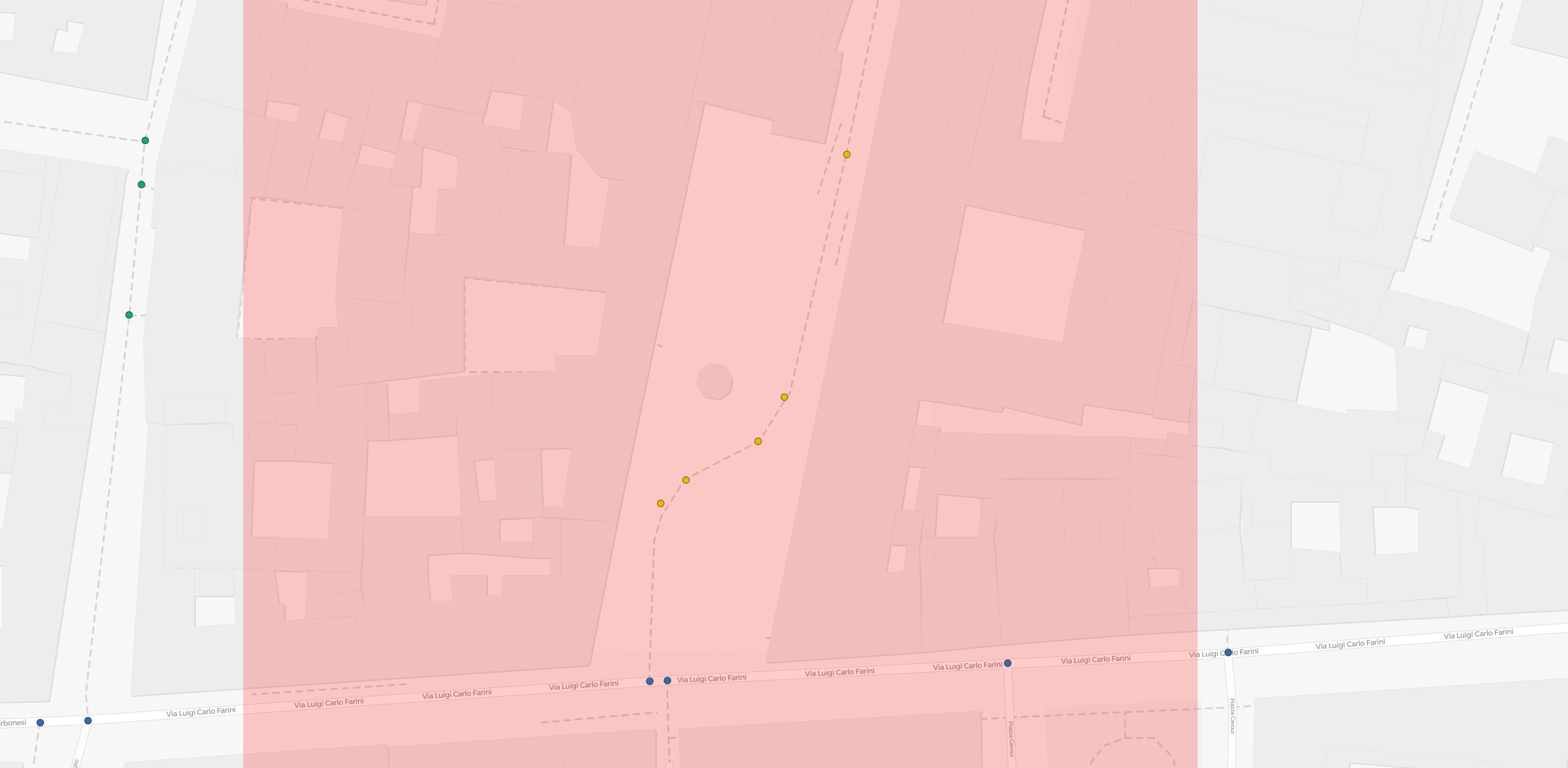
As an example, I’ll refer to the small stretch of cycleway highlighted in the images above. Such path is crossed by three trips, of ids 3, 5 and 8. It is a relatively isolated path, so it is sure enough that all the three map-matched trips should point to the very same osm way. Disabling the simplification adds one additional point to every one of these trips, but these additional points do not coincide.
Therefore I’m confused. Having disabled the simplification, shouldn’t I obtain all the nodes that are present on the path in all the three cases? I.e. should’t three trips result in the very same nodes on that part?
Thank you,
Pietro