As far as I understood the landmark algorithm, each of them increases the memory consumption. Wouldn’t it be better to use a single area covering Europe and avoid an additional subnet?
How does the area file work for a world import? Shouldn’t there at least be different areas for North- and South America?
You mean each subnetwork? The landmark splitting just increases the density of landmarks for an area to improve query speed significantly. It does not increase memory usage. E.g. when you define 20 landmarks and use the landmark splitting then those 20 landmarks would be responsible for Asia+Africa+Europe. I.e. every node in this area would then have a “from” and “to” weight to those 20 landmarks, with weights with extra ordinary big numbers and using them for guidance is less efficient (as the difference is smaller I think). Now with the landmark splitting we have 20 landmarks for every subnetwork i.e. a node in Europe has “from” and “to” weights to the 20 European-landmarks (and only to them!) and a node in Africa has the “from” and “to” weights to the 20 African-landmarks.
They are not connected via OSM it seems, so we do not need to split them?
To do this we would have to split the geographical areas I think and adapt the import procedure or sort the nodes somehow (probably related to this issue). Currently we store the “from” and “to” weights of all nodes in the same big table. And node1 could be in Europe, node2 in Africa and node3 again in Europe. We know this row-to-landmarks relation only from another small info (1 byte per node) to which of the 128 subnetworks a row belongs - see SubnetworkStorage. Obviously the world has more than 128 subnetworks but we only need to build landmarks for bigger subnetworks.
No I meant to improve the heuristic. Just looking at the screenshot made me think it would be nice if some of these landmarks in Turkey were in Europe But yeah to achieve this we can also increase the landmark count for all areas.
Wouldn’t it be better to scale the landmark count based on the subnetwork size(e.g determined by node count)? Smaller subnetworks like Turkey and Iran probably don’t need 16 landmarks or more.
Yes, this sounds like it would be closer to ideal, but the way I understand @karussell this is currently not easy or not even possible because of the way we store the landmarks(?).
I do not see a way to make storing this more efficient (we could always leave the space unused for the smaller area but it does not hurt to use these landmarks). I.e. if we increase landmark count for Europe then we can use a smaller landmark count for areas like Turkey but the columns would be just empty and unused. To make it decoupled we would have to split the underlying graph so that we could use one landmark table (with different landmark count) per subnetwork. Or we use a HashMap instead of an array for everything but this would mean a much larger memory usage even if we safe a few entries for the smaller areas I think.
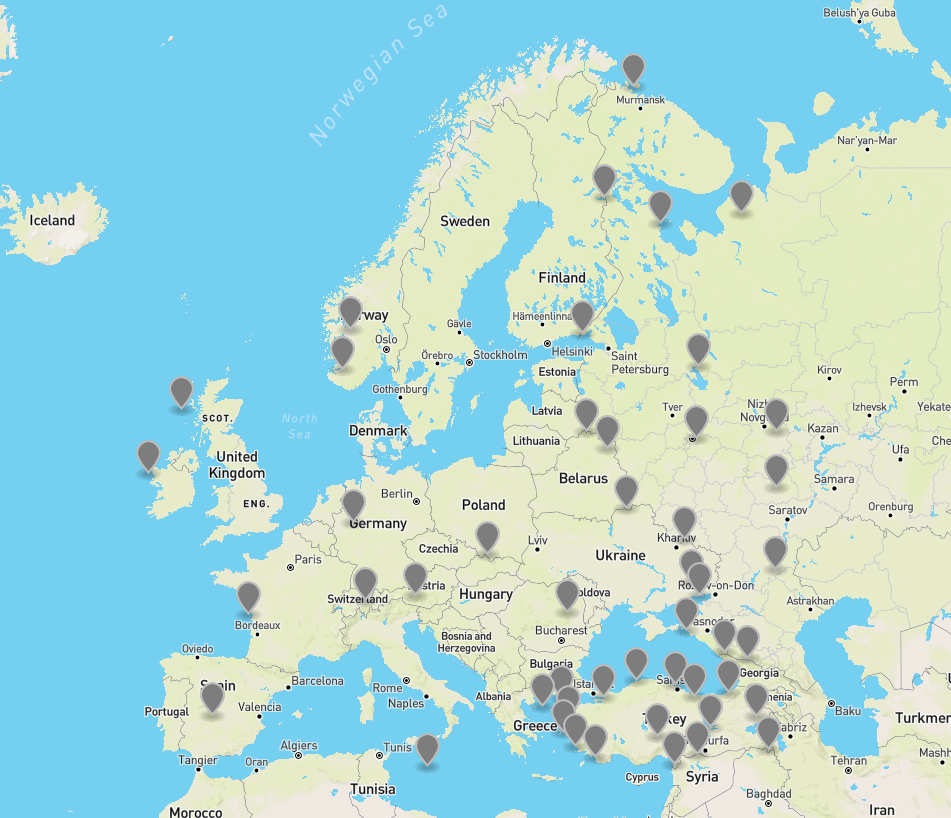
 But yeah to achieve this we can also increase the landmark count for all areas.
But yeah to achieve this we can also increase the landmark count for all areas.