I work for for wecity - a mobile app which rewards sustainable mobility - and I’m using the map-matching tool for the creation of maps which show the “safety” (/cyclability) rating of various OSM edges, as evaluated from the feedbacks uploaded by the app users along with the GPS traces of their bike commutes.
A rough explanation of the process leading to the maps:
-
- I receive sets of “raw” GPS points (subject to error, thus in general not laying on any OSM edge), each of them representing a trip performed by a user, and the corresponding value from 1 to 5 representing the overall safety rating of the trip as evaluated by the user.
-
- I use a python script (which sends a map-match request to my locally hosted graphhopper) to convert such trips into sequences of edges (each edge is intended as an unordered set of two points) that actually lay on the OSM graph, and store the sequences into a postgis database along with their safety ratings and a few other attributes.
-
- I use spatial queries for grouping the records by edge, and compute an average rating for every unique edge within a set of map-matched trips (such set is selected filtering the whole map-matched trips database with conditions on the trip bounding box - e.g. the trip is contained within a given city administrative boundary - and/or on other trip features - e.g. datetime).
Nonetheless, my first attempt at plotting the map highlighted a relevant issue: in some regions of the map I had many overlapping edges, with different rating values. Since graphhopper should return a sequence of edges “picked up” from a set of edges (the graph) which does not change between the subsequent map-matching processes, I thought that two map-matched trips that overlap on some part should contain the same points for regarding the road stretch on which they do overlap.
After being partially illuminated by this topic, I added &wayPointMaxDistance=0.0 to my request. This significantly reduced the problem. From what I understand the final map-matched path (in terms of list of points) is simplified before being returned as the map-matching result: I guess such simplification is applied by removing some of the points as long as their removal does not change (beyond a certain threshold, which I did set to 0.0) the shape of the total path.
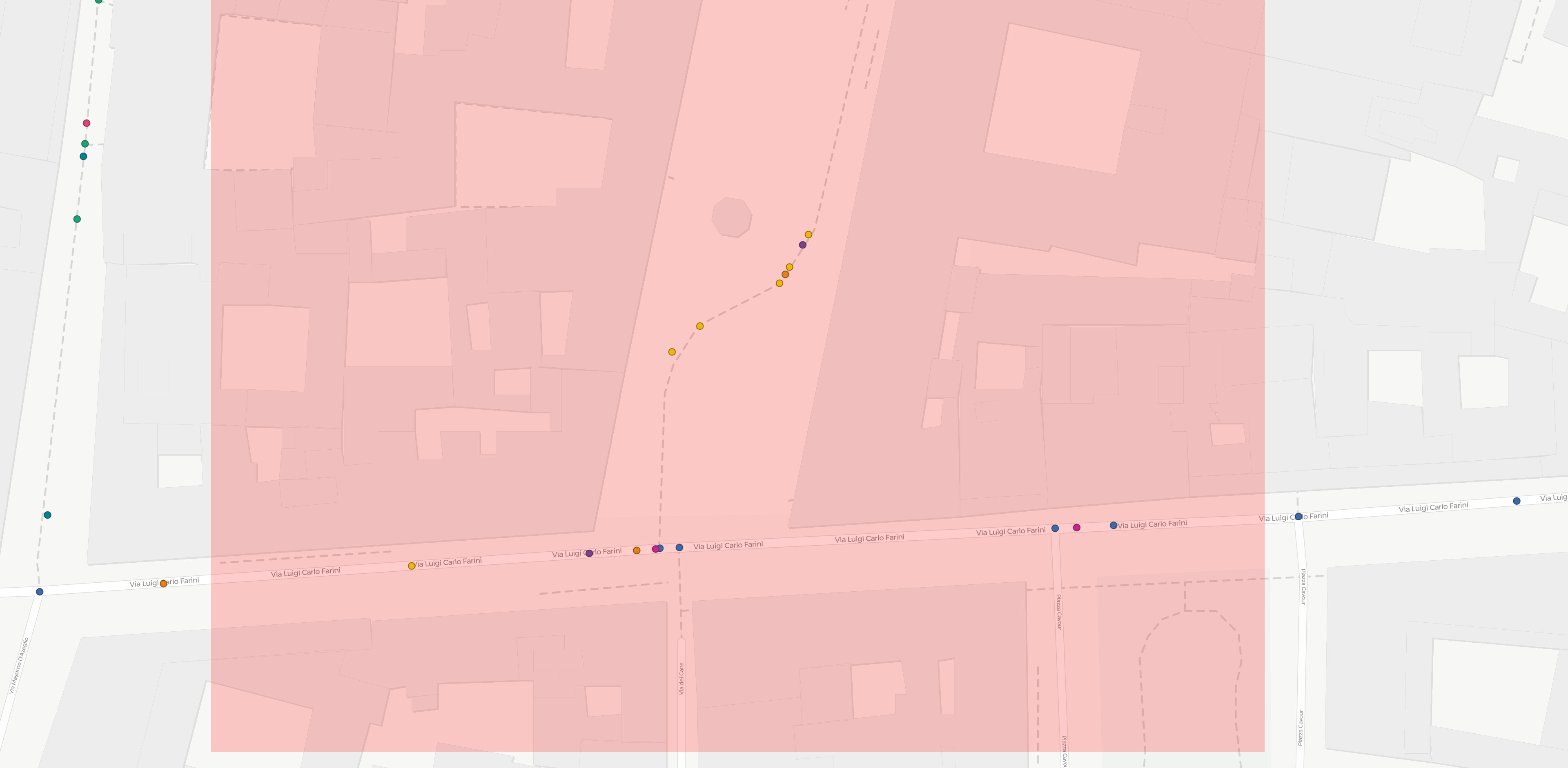
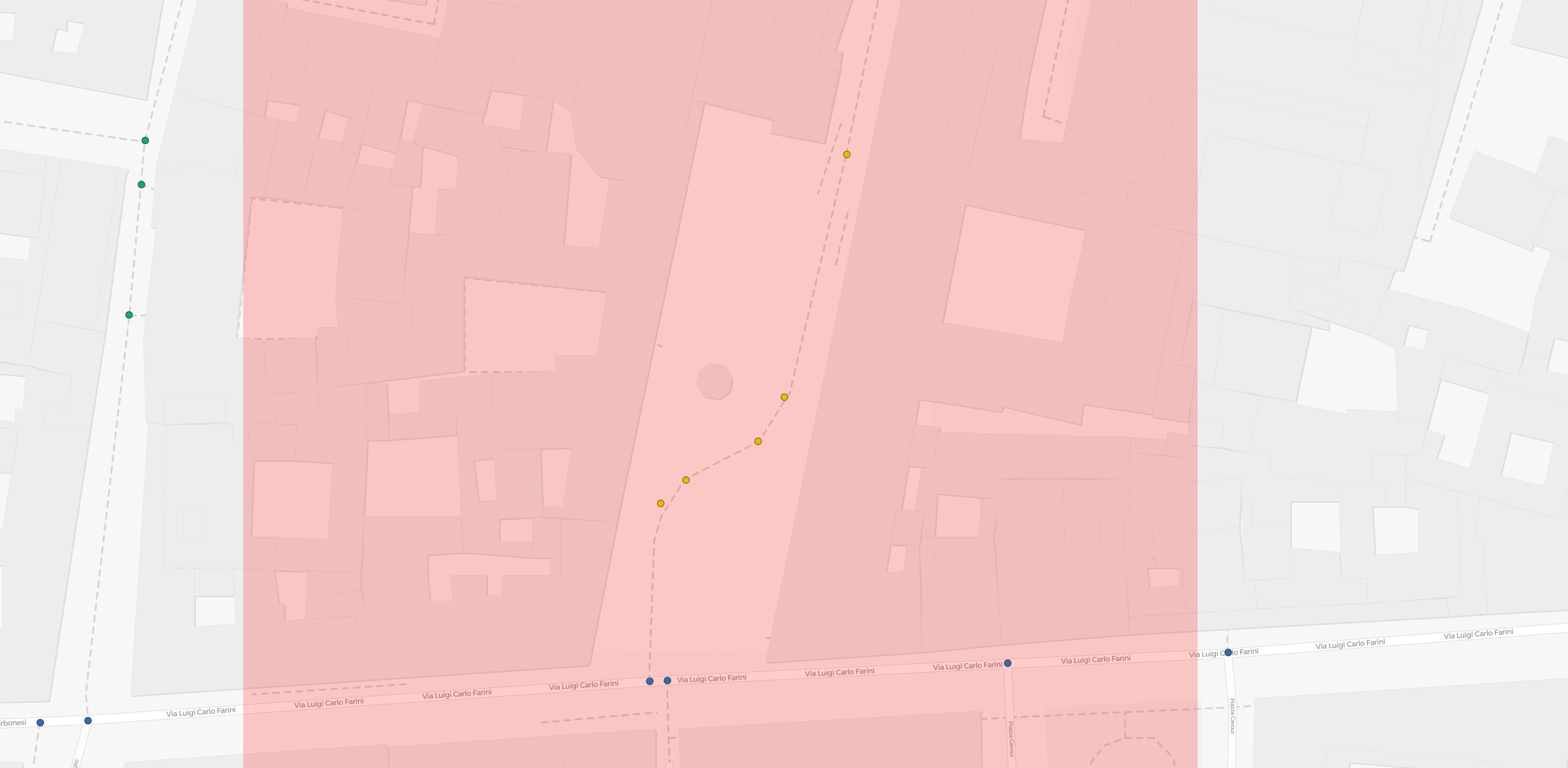
Still, my trick didn’t fix all cases. I noticed that some nodes are still being skipped by my map-matching response:

E.g. in the map-matched trip (red line, yellow points) reported above some nodes (their approx location marked with ?) – that must be present in the grapphopper graph as they’re shared between multiple edges – are skipped. I guess this is because their removal does not change the shape of the final polyline, as the path is perfectly straight in the proximity of such nodes.
Still, for a successful and unambiguous visualization I would need to obtain the full node list at every match, and zeroing the threshold is clearly not enough.
Since I don’t use graphhopper from a java environment I can’t reproduce some of the suggestions from the topic I mentioned, so I’m wondering if there’s a way to fully disable the simplification (response simplification only, I don’t care about graphhopper graph being less detailed than the OSM graph) by changing some lines in the core. Does anybody knows where response simplification is applied?