Hello guys,
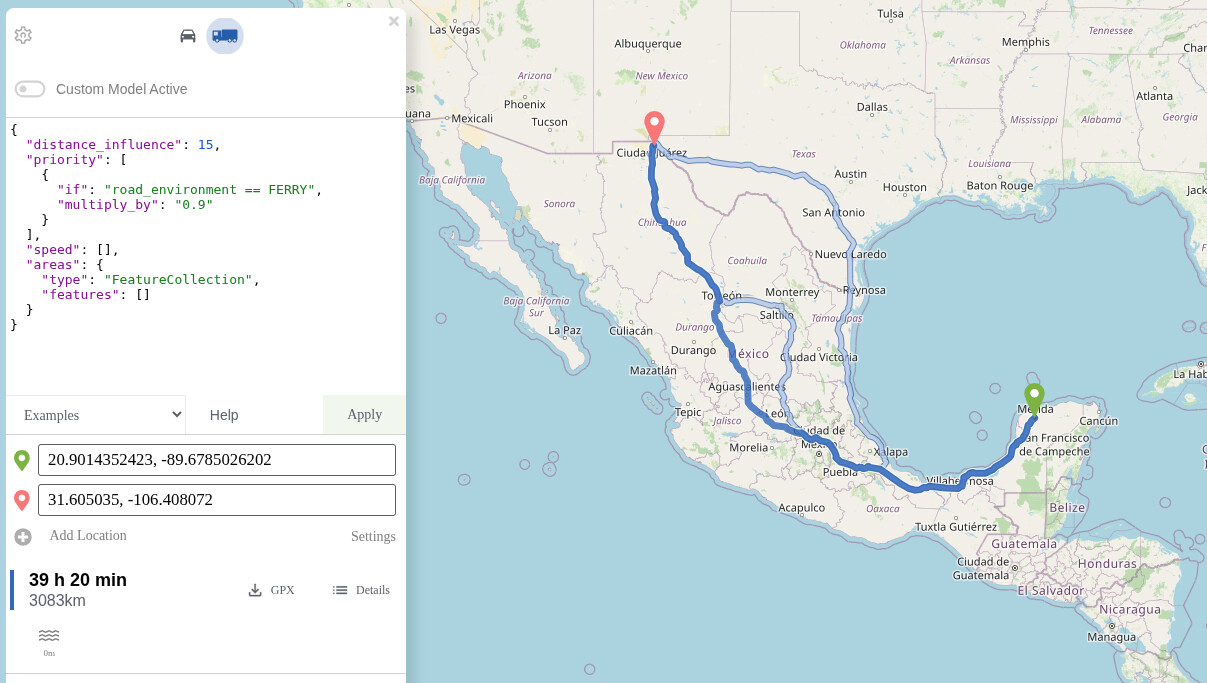
I’ve been trying to resolve a certain route in a graphhopper instance running locally, but when I enable the custom_model, I receive the error “Using the custom model feature is unfortunately not possible when the request points are further than 500 km apart.”.
I realized in graphhopper web (maps: “GraphHopper Maps | Route Planner”), the error is a little bit different: “Using the custom model feature is unfortunately not possible when the request points are further than 700 km apart.”.
I also tried to solve this route using http request over postman, and the time with ch.disabled: true/false are very, very different.
Using false, I get responses under one second, and with true, It takes more then twenty seconds.
Another interesting things is, using https://explorer.graphhopper.com/ using the same payload (listed below), even with ch.disable, true or false, I do not receive any response above two seconds.
{
"points": [
[
-89.6785026202, 20.9014352423
],
[
-106.408072, 31.605035
]
],
"profile": "truck",
"locale": "pt_BR",
"pointsEncoded": true,
"instructions": false,
"details": [
"average_speed",
"leg_distance",
"leg_time"
],
"algorithm": null,
"customModel": {
},
"ch.disable": false
}
1 - Where I can configure this limitation of 500/700 km in my GH instance?
2 - Why my json request have such different response times, with “ch.disable”: true? And how can I improve my processing time of ch in my local instance?
here’s my graphhopper configuration file:
graphhopper:
datareader.file: ""
custom_models.directory: /graphhopper/profiles
profiles:
- name: car
custom_model_files: [ car.json ]
- name: truck
weighting: custom
custom_model_files: [ truck.json ]
profiles_ch:
- profile: car
- profile: truck
profiles_lm: []
prepare.min_network_size: 1000
prepare.subnetworks.threads: 1
routing.non_ch.max_waypoint_distance: 100000000 #100.000.000
routing.max_visited_nodes: 15000000 #15.000.000
import.osm.ignored_highways: footway,cycleway,path,pedestrian,steps # typically useful for motorized-only routing
index.max_region_search: 30
graph.location: graph-cache
graph.dataaccess.default_type: RAM_STORE
graph.encoded_values: hgv,max_weight,max_height,max_width,toll,car_access,car_average_speed,road_access
server:
application_connectors:
- type: http
port: 8989
bind_host: localhost
max_request_header_size: 50k
request_log:
appenders: []
admin_connectors:
- type: http
port: 8990
bind_host: localhost
logging:
appenders:
- type: file
time_zone: UTC
current_log_filename: logs/graphhopper.log
log_format: "%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n"
archive: true
archived_log_filename_pattern: ./logs/graphhopper-%d.log.gz
archived_file_count: 30
never_block: true
- type: console
time_zone: UTC
log_format: "%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n"
loggers:
"com.graphhopper.osm_warnings":
level: DEBUG
additive: false
appenders:
- type: file
currentLogFilename: logs/osm_warnings.log
archive: false
logFormat: '[%level] %msg%n'