Hi guys.
I am migrating from 0.11 to 1.0. Generally nice progress, really appreciate your work, good idea with enums and encoded values.
But.
I have one request - please, think up encapsulation policy.
For example, if someone wants to provide his own algorithm factory which uses landmarks approximation… it is impossible to do it clearly:
you can make your class in package com.graphhopper.routing.lm because LandmarkStorage is package private
you can also make a workaround like use LMRoutingAlgorithmFactory, then make dummy algorithm like AstarBi and then extract resulting approximator from this algorithm.
You guys don’t have to take my words into account, but please consider that some users are not only using you service - also low level API, like me, which I am migrating for recent 2 weeks already, and long way ahead. Some changes are good, but others… would like to avoid.
Thanks for any response, maybe counterarguments or critism, and regards
Hi, thanks for your feedback. There are indeed quite a few refactorings going on at the moment and more are already planned. First of all the current stable version is 0.13. There is no version 1.0 yet, so I am not exactly sure which migration you are planning to do. Migrating to any pre-releases is not a good idea in my opinion, as there are many changes some of which might be only temporary as well. Which parts of GH can be considered stable and which are subject to (drastic) change is always up to discussion and there is no clear policy for this yet. I think the best thing you can do is to describe in detail what kind of modifications, extensions etc. you are doing or planning to do with GH, such that such kind of use-cases might be considered in future developments. Maybe some of your ideas and changes might even be useful for the upstream project and it would be ideal to add them to the upstream project.
Regarding the things you mentioned here, honestly I have a hard time to follow what you are trying to say. Can you be more specific? What do you mean with ‘SRP’?
Hi, thanks for you reply!
unfortunatelly, I need to migrate now - too much work now, and migrating to 0.13, to later migrate to 1.0… 2x times more work, especially I have a big layer upon GH.
By SRP I mean “single responsibility principle” - class should do just one thing, and nothing more; FastestWeighting by now not only calculatest fastest weight, but also takes into account penalties for private routes and destinations, and this behavior is not considered in ShortestWeighting for example, but is in ShortestFastestWeighting… because it inherits after FastestWeighting… some kind of a bad smell IMHO, even if it is configurable.
Regarding your request about beeing more specific - could you point out your issues about my statement? Don’t get me wrong - just want to avoid spamming.
Also, sometimes commit messages are very hard to follow - for example I have a long way to find where CHWeighting was removed. And in the same commit, to understand changes in AbstractBidirCHAlgo, which was not so quite new, but ‘introduced’ in https://github.com/graphhopper/graphhopper/pull/1850. You know, when I need to migrate some part of my code, and see that some class is no longer available, I need to know what to do in that case. And this way is not so handy
FastestWeighting does one thing: It calculates the edge- (ok and turn-) weights to obtain the fastest route. And like any weighting it needs to deal with private road restrictions etc. as well (just like it is dealing with speeds etc.) But you are right ShortestWeighting does not do that and you already opened an issue for this.
I will try…
What needs to be changed to make it possible then? You have not really explained what you want to do so its hard to guess what needs to be changed. Note that the routing algorithm factory especially might be replaced or changed, because it has several drawbacks.
What is a ‘graph weighting’? What makes you think it wraps all weightings except in node based ch?
Sorry, but this does not seem to be a proper sentence and honestly I have no idea what you mean.
Yes we are trying to make GH also usable as a library on the low level API, but at the same time we are trying to implement new features etc. and there is always a trade-off between going forward and breaking things and trying to stay backward compatible which slows down progress and makes things often too complicated.
Some changes are good others you would like to avoid. But which ones do you like and which ones would you like to avoid, and more importantly why would you like to avoid them and what are better alternatives?
Yes especially in 1.0 there will be many such changes. So many that it became too hard for us to track all these low level changes. Maybe it would be useful to write some kind of migration guide that lists the most important of these changes. Did you somehow record the things you had to change? That would be a good start. The changes of the CH graphs and algorithms are mostly temporary and might only seem useful when they will be completed.
Yes especially in 1.0 there will be many such changes. So many that it became too hard for us to track all these low level changes.
I just have to add that we did not gave any guarantees of a Java API stability (it is a 0.x version after all) and as long as there are no users reporting problems back this likely won’t change as we just can’t know if it is worth the effort at all and where to spend the actual time of documenting this.
I need to migrate now - too much work now, and migrating to 0.13, to later migrate to 1.0
In the current state you should NOT migrate to 1.0-SNAPSHOT, except you are willing to invest some more time to migrate to the final release. It is not released yet and things might still change. Also in general it is better to migrate as often as possible and from one release to another instead of a big jump.
And as @easbar already said: please contribute with your exact problems and how you fixed them and specify exactly what you need. Otherwise we won’t be able to help now and improve our migration strategy for coming releases.
When you included ‘and’ it already told me that it makes more than one thing But a more practical reason - what with bikes, pedestrians? What if you have access to some private areas? Emergency vehicles? What with timely dependant routes (ie. from opening perspective)? What if you don’t care? Just fact that FastestWeighting has configuration destinationPenalty or privatePenalty makes me wonder about SRP. And you will have code duplication, if you won’t make some interitance like BasicWeighting or something, which will include this knowledge. But I think composition is better, but it is just my humble opinion.
I did - I want to provide my own landmark based algorithm. Specifically, my algorithm version for alternatives.
What you should do? It depends on your perspective; if you want to make GH more like an library, propably more public (!= all) methods which can be reused, or expose some high level API which allows to use logic. I think I described steps which I needed to do.
Maybe reducing coupling by dependency injection would help (does not mean any guice or something, just passing list of some interface via constructor). I mean no factory, just filters - algorithms will tell when it can be applied or not, and prepare params based on provided data. This approach seems to be configurable for me.
Maybe a whole my sentence again:
don’t know, I did not make a funcion like ‘graph.wrapWeighting’, so you probably should tell me What makes me think is a link placed in the original post: 58 line in CHRoutingALgorithmFactory (quote above).
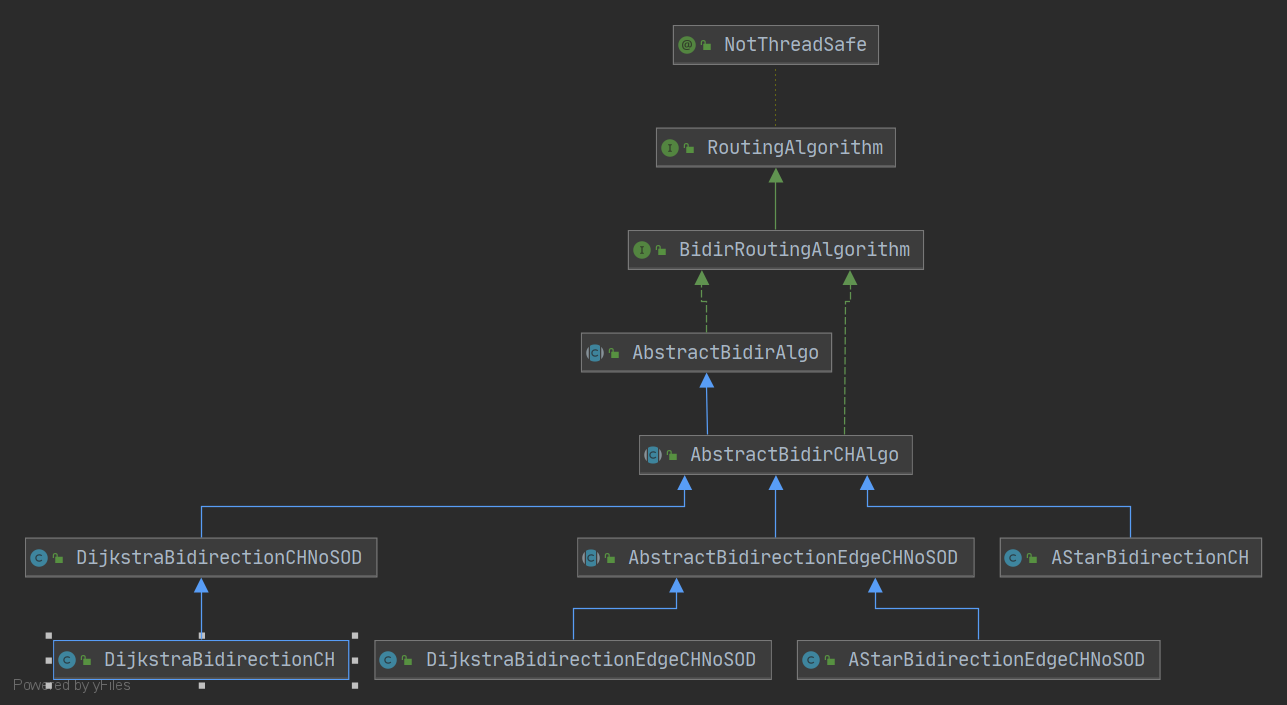
Ok… I meant that you inlined TurnCostWeighting (so it is not extracted elsewhere) into AbstractBidirCHAlgo. Now, please take a look at the dependency graph I included.
You will see that node based algorithms also use turn cost logic, which is unnecessary - they can’t use it in any meaningful way (or am I wrong?).
Yes, I totally agree with you, but there are also some another ways without breaking compability (I know that 0.13 → 1.0 semantic versioning (which is not applied here ) allows breaking changes). Migration steps, deprecations, translations layers… there are many ways.
Yes, I have detailed git log, so when you will finish upgrade (which I hope will come soon) I can contribute a little bit.
Eh, if you can describe what can change, I would appreciate that. For now I noticed about 10% speed degradation in my algorithm… and this is very important, but I have also seen that this is a temporary in github issue and will be fixed later (unfortunately I cannot find it now). I will come back to it later.
The first think, different from ones mentioned earlier, is that I quite often see “OSM” now in the code. Not connected with OSM.
I know that this is your base, but there is not reason for this to place it everywhere (TurnCostParser for example, not talking about EncodingManager).
Ok, first of all - I am not only using OSM. Same way - you use TomTom in your comercial product. But in this way, it sometimes looks strange. Also AbstractFlagEncoder has the same, but ok - this is quite old now.
But if I told about EncodingManager - I needed to add my own TagParsers, even the ones I do not need (performance matters, graph size also)… because of the default in EncodingManager.
Why didn’t you just create OSMEncodingManagerBuilder?
Ok, but this lib already has 5 years. I understand your approach, but… it is some responsibility, regardless it is open source.
Maybe they just don’t migrate or use your service, not algorithms as a code?
I have to, because my work is not full focused on this part and GraphHopper integration. My project employs also other possibilities of route planning like some API usage: HERE/TomTom…). Now I need to migrate because work from external contractors will be done soon and we want to make as few changes as possible to the code.
And 1.0 brings some options I needed (customizable profile per request for example, DataFlagEncoder, was no quite good, props on edges…but it was 0.13 probably).
It would be good to also build CH later, for now I saw ‘it is possible’, but could not make it (…with the new profile, for example for new weight).
Also, I assumed that 1.0-pre31 is quite advanced, and end is close. May I ask when it will come ?
Again, thank you very much for your work - it helps me a lot.
Ok, no offense, but honestly I read your posts several times and I still do not know how I can help you with this. So if you want something to change you have to say exactly what it is.
Ok first of all our graph can have turn costs at some junctions, something like “it takes 40s to turn from edge 20 to edge 58 at node 4” or “you cannot turn from edge 9 to edge 13 at node 6”. From OSM we only get the latter type of restrictions, but for the algorithms it does not matter whether there are turn restrictions or finite turn costs. Anyway, the problem here is that we are not simply routing on this graph, but because our start/target coordinates do not necessarily correspond to road junctions we have to add some extra nodes and edges to this graph. We call them ‘virtual’ nodes/edges and they get other IDs than the original edges. This is done by QueryGraph. Now, when we calculate turn costs we have to be able to do this also for these virtual edge IDs and so we have to use a special weighting (its called QueryGraphWeighting now). Basically using QueryGraph instead of the original graph also requires adjusting the weighting. graph.wrapWeighting(weighting) does exactly that, it takes a weighting and wraps it in a QueryGraphWeighting. Previously this was done by subclassing the TurnCostExtension. Doing this via the wrapWeighting method is still a workaround that is used because of the IMO broken RoutingAlgorithmFactory interface. See also here: Remove TurnWeighting and handle turn weights within Weighting instead by easbar · Pull Request #1863 · graphhopper/graphhopper · GitHub
Wrapping the weighting is only really needed when turn costs are involved, I think that’s why in the line 58 you mentioned its not done for node-based CH, but I think it could just as well be added if that bothers you.
I would like to use LandmarkApproximator.
First, I wanted to create my own by using LandmarkStorage created in GraphHopper but… getter in PrepareLandmarks is package-private. OK, challange accepted.
Because of that in the place of usage I need to
use LMPreparationHandler
each time create the new instance of AStart with proper settings
extract approximator from AStar instance
A little bit complicated, but I think I got the point, thank you.
Nice idea
Thank you for your comprehensive answers and time!
Ok feel free to send a PR that opens/make public what you need. I agree that getting the approximator should be possible also without creating some dummy algorithm and extract it from there.