Hi guys, did you think about making possible to use Node Based with CH. I know that without changes, from algorithm point of view it can be hard because between 2 nodes there can be multiple edges.
But - for those edges where we have turn restriction, it is possible to put dummy node inside, I mean when we have node A and B, and also edges X and Z, where X has turn restriction, we can make node AX, and split edge X into XA and XB. Thus turn cost could work only for A and AX.
If I am in the topic of Turn Restriction, do you have multiple edges restriction on your route map? I mean restriction like extended U-Turn for example 6655738? I spotted many of them.
Hm, sorry I cannot follow your example, can you draw a little map or something? But honestly I do not think there is a way to do this unless you split all nodes, but this will also drastically increase the size of the graph.
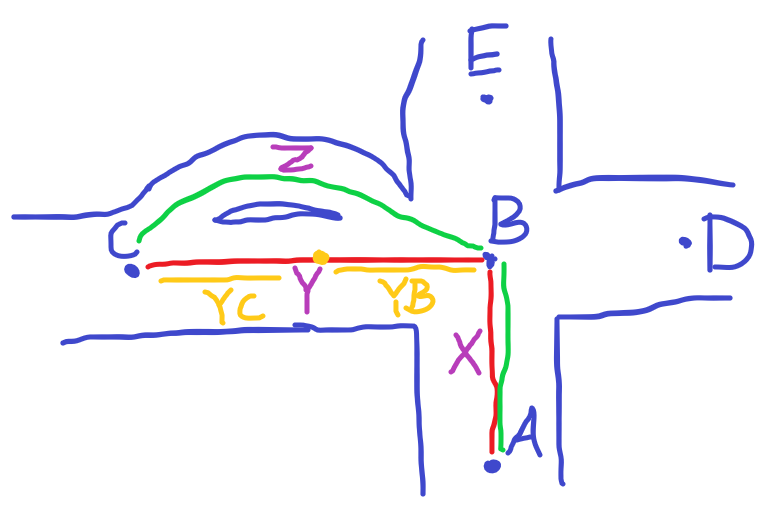
In orange I propose the solution - both YC and YB are derivatives from edge Y split.
Let’s say there is some node Y between C and B, which lies between and thus connects YB and YC. It is sure that there is no other edge between B and Y(node), so restricting this relation should be reliable.
Ah no this does not work in general (not even for Dijkstra). Your example is too simple because there is only one edge going from A to B. What if there was another edge D-B? When you expand node B there will already be some parent node (A or D), but then you cannot differentiate between the two cases anymore (going left is prohibited, but going straight (when coming from D) is ok). So if you start doing this you end up splitting all nodes in a similar way as you proposed.
I know that this is simple, and I did it with awarness.
I solved restricting turn costs it somehow similar way for HERE data.
Maybe not exacly this way, but I managed this by making whitelist of possible routes where turn cost would exist.
In this case I placed above (without ‘dummy nodes’) it would look like from A you have A-C via Z, A-E and A-D, but there is no connection between A-B - it is just removed. From C you have C-A, C-D and C-E. I know that this will make many edges, but turn costs are not so offten comparing to the edges count.
I don’t want to expand node B. I want to split edge Y.
Look, we have relations, for example now relation A-B-C and D-B-C. Why it cannot be replaced with A-B-Y (Y-Node) and D-B-Y? Y in this case have just 2 edges, and thus relation A-B-Y can be safely disallowed.
With ‘expand’ I meant the expansion during the Dijkstra search. Yes you can split edge Y but I think it does not help. Maybe you can convince me by providing some code that does this (just a graph with turn restrictions, the extra nodes you want to add and a Dijkstra that does this correctly). Or even some pseudo code that just explains what Dijkstra does when you include the edge splitting you are talking about and how it respects the turn relation. Honestly I do not think its possible.
Yes, at least now I don’t see it to be possible on the algorithm level - this should be made on graph preparation level when edges are processed. Then no change in the algorithm would be necessary I think.
As far as I know turn cost is calculated durring dijkstra calculation by adding cost when relation is found in TurnCostStorage (right?), so it would be just a key change.
I see that chaning the whole graph to allow turn cost to be possible via node based can be crazy, but node based is both faster in preparation and execution.
Well the key question is: Is it still faster when doing this kind of (and what exact?) extra processing? From all that I know it would only work if we split all nodes into multiple ones so we can distinguish between the different travel states at each node (we have to know where we came from to restrict turns). So this would be a huge increase of the number of nodes (and shortcuts for CH) and it might be just as good or bad as (or worse than) edge-based CH.
I wonder why do you want to split nodes.
Take a look:
edges are loaded from OSM
relations are processed
for relations where turn restriction was detected terminal (or even all) edges are searched
original terminal edge is replaced with 2 edges, and dummy node is inserted between, so original relation A-B-C (in edge notation X-Y) now is A-B-Y (or X-YB if edges)
everthing stays as it was before - the only difference is that we have different mapping of turn restriction to avoid confussion which edge is actually restricted - that is the reason why I trying to find some workaroud, because this seems to be the reason why turn cost cannot work with node based, right?
if the original edge is detected somewhere (turn relations is the only possibility now, right?) some lookup need to be done to replace edge Y with YC and YB depending on the source node. But in general edge Y does not exist any more.
If it is cumbersome - don’t know. For sure another mapping is necessary because all original edge (Y) would be replaced with YC and YB. Those would have the same properties and a half of the length for each.
Also, as I said before I did much more complicated modification to catch all turn restrictions (longer than 2 edges) for Here data, where you have much more detailed edges (and much more of them), more relations I think. I did it as a whitelist of possible routes where turn relation is detected on the junction. It does not work for CH however in node-based… because still primitive 2-edge based restriction resolution is required (if you split junction for single routes still u-turn is possible).
But - what I want to say - It did not increase processing time a lot, whereas edge based does it - even 10 times.
I mean the same as you do: You are adding some proxy/dummy nodes (like the one between B and C) to have some extra edges. The problem with this approach is that you cannot just do this with the nodes where there are turn restrictions (its easy to see when you are thinking about what Dijkstra does when running on the graph with the extra nodes and for (node-based) CH its the same problem, it does not go ‘away’.
Yeah, I was aware of that Dijkstra problem (…somewhere on back of my head), but though that the bigger is ambiguity ‘what edge is restricted between nodes’, but sure - solution I proposed is so trival that you probably took it into account before.
And also - without algorithm analysis - I thought you solved that with edge based, and this ambiguity is the only problem now.
Just wonder if there is some way to solve this… maybe on EncodedValue level then? but those are only for edges…