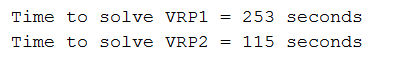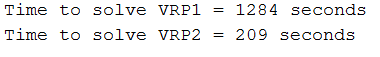I’m using vehicleRoutingCostMatrix. I have created a testCode where I create two VRPs with methods described above. For 120 jobs method 1 takes 253 seconds, with method 2 it takes only 115 seconds.
I suggest also what @jie31best proposed. Use FastVehicleRoutingCostMatrix which is Array based instead of VehicleRoutingCostMatrix being Map based. I assume that differences in performance are caused by the Map and the size of the Map, but I am not sure. Would you mind to conduct your experiments with FastVehicleRoutingCostMatrix?
BTW: I dont use the Map based matrix anymore since performance is significant worse in comparison to FastVehicleRoutingCostMatrix.