I may have a requirement coming up which would include slowing down road speeds in some major cities. Considering London, for a given type of road - e.g. a 30 mile/hour max road - in central London due to permanent congestion you’d probably never see vehicles travelling over 20 miles/hour. This isn’t a legal speed limit of-course, it’s just a typical average and so (presumably) it’s unlikely to be included in any OSM data. My understanding is that Graphhopper just uses a default speed based on road type, which in this scenario would need to be lower in London than the rest of the UK, and therefore currently Graphhopper will not account for this?
Two questions.
Is there any existing functionality in Graphhopper to override default speeds for specific geographic areas?
If not, what would be your recommended technical design to implement this?
If I needed to implement this, I would be happy to add it to the Graphhopper open source code base. I’m thinking that during the build process it would be useful to have an additional (optional) input file containing polygon boundaries (e.g. central London) together with override speeds for different road types. The graph build process would then test if a road segment was contained within a polygon and utilise the override speed for the road type if so. I can see clients wanting to tweak the speeds, so it would be good to use an external file format that’s relatively easy to edit (e.g. JSON with geometry in WKT, or maybe a CSV file). The graph build process would need to do an efficient polygon-line intersection type lookup, to determine which polygon a road sits within (if any), but this could presumably be done relatively efficiently using bounding boxes and a quadtree-like approach.
Any implementation would need to be compatible with contraction hierarchies (i.e. I’d ‘bake’ the override speeds into the graph).
The graph build process would then test if a road segment was contained within a polygon and
utilise the override speed for the road type if so
I fear a simple approach won’t scale for world wide usage, having hundreds of polygons. Instead an approach like you describe (quadtree) and which was partly implemented in one of the issues should be followed using a kind of a location index/grid.
Thanks. If I need to do this, I’ll take an in-depth look at those issues you referenced and the partial implementation you mentioned, and then go from there.
For the algorithm, off-hand I was thinking have a quadtree which recursively split whenever the quadtree node contained a polygon boundary, and allow splitting of nodes until you get say 10m x 10m sized nodes. You’d do this as a preprocessing step at the very start of the graph build process, before loading any road network data from the .pbf. So you’d only have nodes split to ‘high resolution’ along the boundaries of the polygons (which would probably therefore scale to world wide usage). Ignoring the issue of multiple overlapping input polygons for the moment, each node would either be totally inside, totally outside or on the boundary of a polygon.
You then just run an intersection test for each road edge geometry against the quadtree nodes only (i.e. not against the initial polygons) and apply the override speed if the road edge’s geometry intersected one or more quadtree leaf nodes which are either contained or on the boundary of the polygon. You could speed up this test by using a bounding box for the edge geometry so for the most time you’re testing intersections between bounding boxes. You then only test the actual road edge geometry if you get a bounding box intersection (so cheap test first, then expensive).
This approach should be reasonably efficient - i.e. I’d expect it to scale world wide (and I imagine there’s probably already code within Graphhopper I could call to help me with this).
I’m considering implementing this in the near future and it would be good to have some feedback on technical design. It seems like the least-development path is to subclass CarFlagEncoder (call it say CustomSpeedsCarFlagEncoder?) and use the artificial “estimated_center” tag you add during the preprocessing to determine if an edge is within a polygon. As far as I can tell, flag encoders don’t have direct access to the edge geometry, only “estimated_center”, but this is probably good enough for our purposes (and using a single point simplifies the query).
When CustomSpeedsCarFlagEncoder is created it will be given data from either a single GeoJSON file or set of GeoJSON files containing (1) the polygons, (2) a priority level for the polygon (when 2 or more overlap), (3) override values for defaultSpeedMap in CarFlagEncoder (default to CarFlagEncoder values when no override is present), (4) a speed multiplier to apply when the GeoJSON doesn’t store specific override speeds for road types (e.g. use multiplier 0.7 to slow down by 30%). (2)-(4) would be stored within the GeoJSON properties.
Internally CustomSpeedsCarFlagEncoder would use some kind of suitable quadtree-like lookup (as discussed previously) for the polygons in the GeoJSON. It would perform the spatial query for a way on “estimated_center” in its override getSpeed(way) method and return the speed based on the highest-priority polygon containing the “estimated_center” or the default from CarFlagEncoder if no polygons found. As far as I can tell CarFlagEncoder.getSpeed is only called once per way and this is only during the graph build process - is this correct?
The spatial query would be performed in lat-longs which works everywhere except for countries which cross the 180th meridian (see https://en.wikipedia.org/wiki/180th_meridian), so basically it wouldn’t work for the Eastern tip of Russia or for Fiji. The alternative would mean doing some clever spatial projections - which seems overkill at this point.
There’s a few different online editors out there for GeoJSON so this should help with other people creating their own ‘speed tweak’ files. Ultimately it should give Graphhopper users a way to specify country-specific and city specific speeds using their own GeoJSON files (which hopefully they’d add to the Graphhopper project).
It would be really nice to have such a “custom speed per area” feature!
As far as I can tell, flag encoders don’t have direct access to the edge geometry, only “estimated_center”
You can get full geometry but we should probably only care about a center or just start and end point for the initial version.
When CustomSpeedsCarFlagEncoder is created it will be given data from either a single GeoJSON file or set of GeoJSON
I would prefer to abstract everything away as much as possible with as few dependencies as possible. E.g. defining different speed profiles per area ID in a HashMap for the encoder and the area ID of the current way is is determined outside of the encoder, e.g. in OSMReader setting this ID as special tag e.g. assume custom speeds per country the OSMReader sets the country but we could make it more generic and let it specify some kind of area ID. This way all other encoders would be able to consume this.
return the speed based on the highest-priority polygon containing the “estimated_center”
Also here I would try to reduce complexity (at the beginning) and just require that the polygons must not intersect or if they do the first specified one will be picked.
The spatial query would be performed in lat-longs which works everywhere except for countries which cross the 180th meridian (see 180th meridian - Wikipedia)
Why would it fail if e.g. the polygons are splitted before feeding to the lookup index?
Ultimately it should give Graphhopper users a way to specify country-specific and city specific speeds using their own GeoJSON files (which hopefully they’d add to the Graphhopper project).
Yes, we should make this as easy as possible e.g. already grabbing the boundaries of all countries and just requiring the contributors to fill in their defaults.
For this kind of situation we could just say the “smallest area polygon wins” (and so not have to explicitly define a priority, just use a sort-by-area polygons to generate a priority). However calculating a polygon’s ‘area’ using a lat-long projection is a bit dodgy, if not wrong? (Really we should calculate area using a spatial projection to a local Cartesian grid, but I want to avoid having to project…). On a smaller scale calculating ‘area’ using lat-longs should be OK though.
See first answer here for a good explanation on the issues with calculating areas from lat-longs if we use raw unprojected lat-longs. See here for the complications involved in doing it properly!
I’ve started work on this. In the short term (maybe 6 months) I need compatibility with Graphhopper v0.5, so I’m putting this into a separate library which can be hooked up either with v0.5 or the latest Graphhopper. The aim is that you just need a couple of lines of code to hook it into either version.
The library will be Apache-licensed and use Maven. In the future it can either just be copied into the Graphhopper project (i.e. I create a GitHub pull request) or I could put it on Maven central and you could link to it that way (I have no preference either way).
The first version is going to be as simple as possible, but I suspect I’ll need a v2 pretty soon after with some support for smoothing. I worry that (for example) a 30% discontinuity in road speeds across the polygon boundary might create visible effects with the routing. The solution would be some kind of smoothing technique to merge the speeds a bit around the edges (which would be more like what you’d see in real-life).
Thanks a lot! For which coverage did you try this? Or do you have some numbers about memory consumption e.g. for a German sized country?
The library will be Apache-licensed and use Maven
Nice - thanks for contributing this!
In the future it can either just be copied into the Graphhopper project (i.e. I create a GitHub pull request)
Yes, something like this would be really appreciated. Still before it would need some unit and integration tests (Then it is also more obvious how to use it) and also an integration with the recently introduced json wrapper (probably not much work, not sure).
Issues vs. discuss is hard to decide
I still prefer discuss a lot more due to better email management (e.g. delayed email or no email at all if I’m online)
The work has moved to this repository. I’ve got it working and tested (primarily tested with Graphhopper v0.5), to the point where it does what I need it to, so I need to pause working on this for a while now to catch up with some other projects.
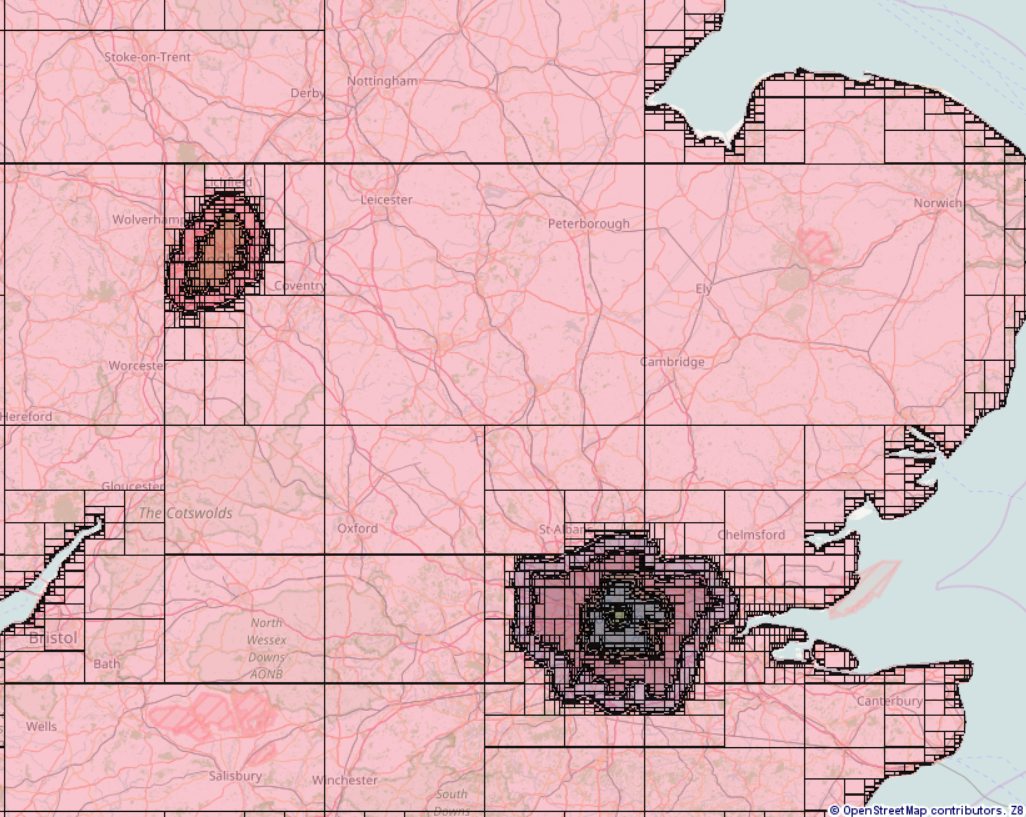
I’ve been testing building the graph for the UK. The biggest bottleneck is building the spatial tree for the regions, which takes a similar amount of time to building the graph itself with contraction hierarchies on. Once the spatial tree is built there’s little overhead with using it (the lookup from road centre to region is quick). I’ve therefore added support to build the spatial tree in a separate step to building the graph, so you can build the tree once and then tweak the speed rules without rebuilding it each time you rebuild the graph. This creates another bottleneck though – the size of the JSON containing the built spatial tree. In my tests for the UK with 100 metres resolution in the spatial tree it was around 80 MB, for the whole planet you’d probably have a few GB of JSON (which might not be manageable). We probably need a compact binary format for the built spatial tree instead (the file size could be 10 or 100 times smaller than current with a bit of work). The building of the tree itself is relatively intelligent with an algorithm optimised for our purpose.
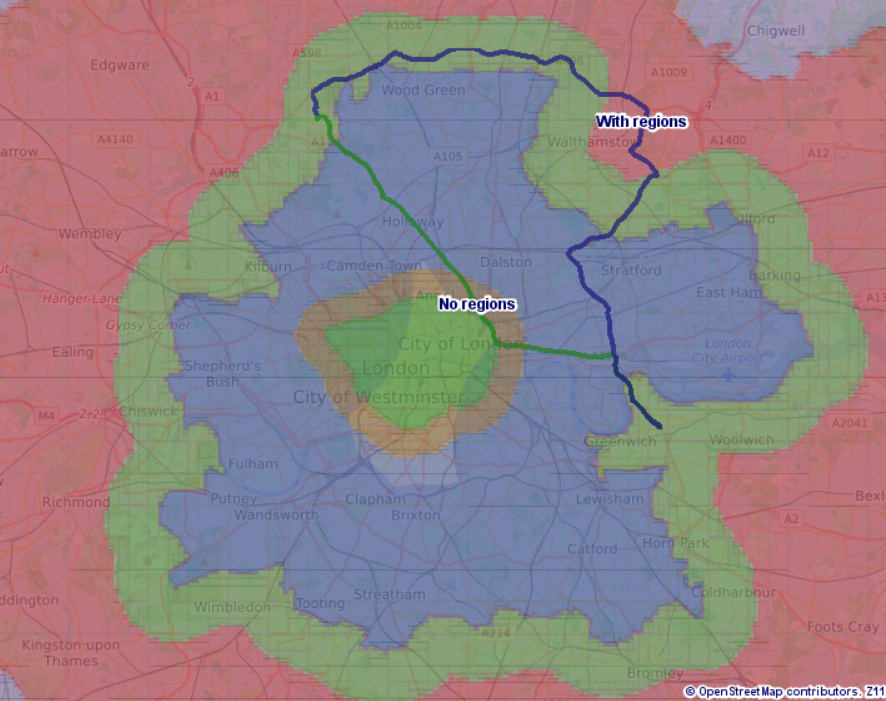
Driving through central London has been slowed down heavily (each shaded area is a separate speed region) so with speed regions on the route goes further out where its quicker, without speed regions it takes the more direct route close to central London.
It would probably help a little bit, but you’d need it simplified to a polygon comprised of lots of vertical lines (lines of constant longitude) and horizontal lines (lines of constant latitude) to be significant, as a diagonal edge on a polygon could still cause lots of nodes. Also you’d have issues dealing with multiple countries with a common land border (i.e. not islands), you wouldn’t want to distort the border too much.
I suspect (but haven’t tested) that with a compact file format for the built tree, or building the tree on the fly from uncompiled when you create the graph, you’d probably still be able to run it on planet.osm without polygon simplification. Also if your tolerance is a lot higher - for example 1 km - the tree is a lot smaller.
For world wide usage the preparation time is currently too slow. But we could just create a lookup interface for that with different implementations.
for example 1 km - the tree is a lot smaller.
This would be too big e.g. for inner-city detection and smaller cities/villages. When we played with a ‘cell’-approach we had 500m which was still several times suboptimal, but going smaller would have been too big as we did not use a tree (just a plain array and there is too much spaces wasted for the ocean ;))
I hope I’ll have a bit more time in the next weeks to go over this in more detail. Looks like a very neat feature.